
NOSA: 原生可卸载稀疏注意力
2026/01 黄宇翔 @清华大学
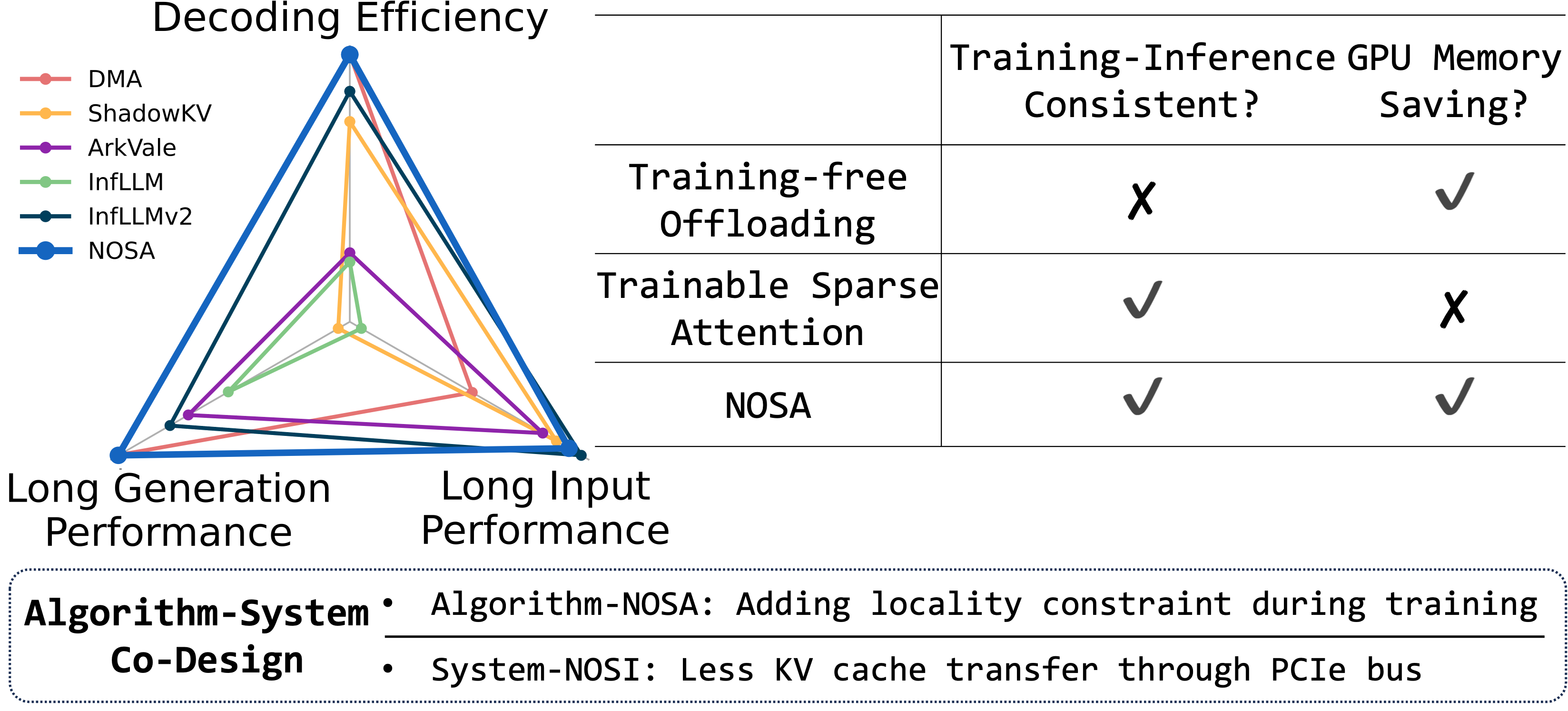
简要总结: 我们在论文中提出了一种原生可卸载的稀疏注意力NOSA,并且实现了一个简单的推理引擎以测试NOSA的batch吞吐。在NOSI上推理NOSA,可以获得5.04×, 1.92×, 与1.83×更大的batch解码吞吐,与FullAttn, InfLLMv2, ShadowKV相比。
关于稀疏注意力的思考
稀疏注意力与KV cache优化是两个历史非常悠久的领域。前一阵与某位葡萄牙大牛教授聊天,意识到稀疏注意力的研究历史可能从10年或者15年前的LSTM时代就开始了。进入Transformer时代,BigBird等方法也存在了相当长的时间。在大模型时代,稀疏注意力通常和KV cache优化并列,因为一些经典方法例如StreamingLLM、H2O、SnapKV在稀疏了注意力模式的同时也可以减少一些KV cache。这方面的文章截止到2024年,可能有上千篇之多,也许没有任何一篇Survey能够将其全部囊括在内,这也是这一领域在2023-2025年的ICLR投稿中持续热度前5的原因。
2025年以来,稀疏注意力的设计朝着原生化的方向前进,以Deepseek NSA、Kimi MoBA为代表的可训练方法成功将稀疏注意力整合到了长文本持续预训练中,稀疏注意力本身可导,模型可以在训练中适应稀疏模式。我们团队也有一篇相似的工作InfLLMv2,近期刚被ICLR 2026接收,给出了一个高可复现性且非常简单有效的可训稀疏模式。这些可训稀疏注意力主要消除了训推不一致、prefill decode不一致等可能导致掉点的原因,从而使稀疏注意力真正变得工业可用。然而,这不禁让人思考,有了稀疏注意力,传统的KV cache优化还被需要吗?
纵观一年来的可训稀疏注意力的发展,我们可以看到大家追求的共性:
- 训推一致:消除训推不一致导致的掉点,可以在训推交替的场景(例如RL)中使用;
- prefill decode一致:模型可以支持长输出,不至于因为每一步decode的稀疏性能损失导致模型生成崩掉;
- 同时减少计算和访存:无论是NSA还是InfLLMv2,都采用了双阶段稀疏注意力的方法,能够在prefill中省计算,decode中省访存。
然而,还有一些其他推理优化能做得很好的事情,可训稀疏注意力不能做到:
- 平衡计算与访存:如果不考虑Deepseek家模型的极端情况,大部分模型上稀疏注意力,在decode阶段并不能消除memory bound的问题;
- 增大batch size:由于访存仍然是瓶颈,增大batch size依旧是最有效的提升decode吞吐的手段。但是由于稀疏注意力不减少KV cache的大小,batch size依旧被显存大小限制。
我们需要什么样的稀疏注意力与KV cache优化:
-
足够稀疏:同时省计算与访存。省计算可以加速prefill,省访存可以加速decode,这是最朴素的愿望。
-
足够原生:我们希望一个优化方法可以同时在短文本通用任务、长文本输入、长文本输出(深思考)上都不掉点。
-
对大batch足够友好:可以用一些KV cache优化的手段,例如压缩、丢弃、量化、卸载等方法,让batch size不被显存大小限制。
在图1中可以看到,可训稀疏注意力不满足3,传统的无训练KV cache卸载不满足1,2。因此,需要设计一种方法同时满足上面三点,实现性能与大batch解码吞吐的平衡。
魔改可训稀疏注意力
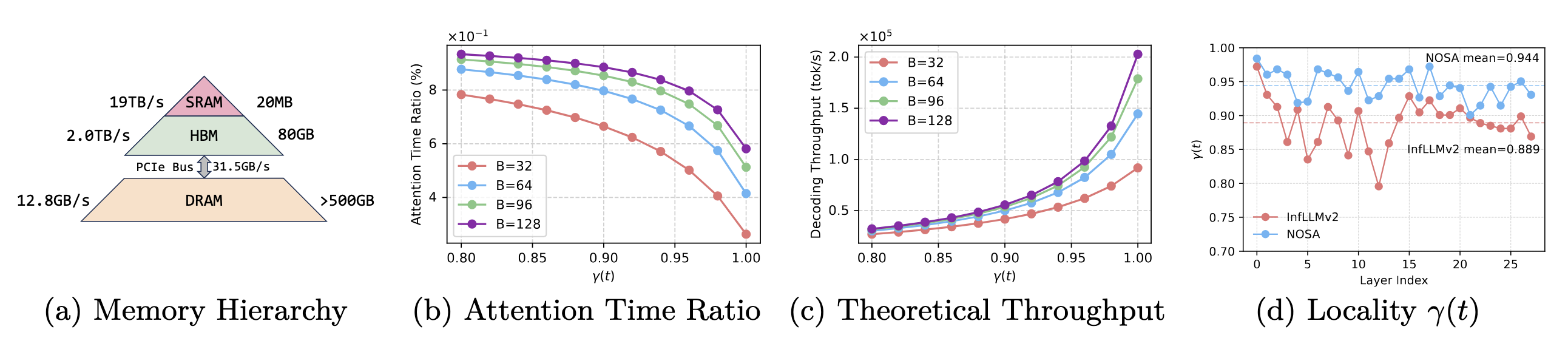
一种非常有效的增大batch size的方式是KV cache卸载,即把没有激活的KV cache存在CPU上。显然,可训稀疏注意力并不能直接做这件事情。我们首先先考察,可训稀疏注意力是否有潜力来做KV cache卸载。
从设计而言,可训稀疏注意力和良好的KV cache卸载系统之间只差一步。每个decode token只会激活一部分上下文,因此天然地,我们可以将其他没有激活的上下文放在CPU上,每次将激活的部分取到GPU上计算。然而,这要求相邻token激活的上下文尽可能相似,不然会有海量通信卡在PCIe上造成解码吞吐报废。
在PG19上计算InfLLMv2相邻token激活上下文的重复比例(我们在论文里把这个指标定义为局部性),如图2d所示。可以看到,大部分层的局部性高于80%。这意味着如果我们激活4K长度的上下文,平均只有约800个token需要从CPU传到GPU上。看上去,可训稀疏注意力的局部性很好,已经超过了类似工作汇报的指标(例如ShadowKV的局部性大约在70%上下浮动)。
但是80%的局部性真的够吗?如图2b、图2c所示,理论上大约有80%左右的时间花在注意力上。理论上,如果把局部性通过某种方式从80%提升到90%,推理时间可以降低到原本的1/2甚至1/3。这说明,如果我们进一步提升选上下文的局部性,就有可能得到更加大的解码吞吐。
由此可见,限制在KV cache卸载系统里运行可训稀疏注意力的核心在于token选择的局部性并不够高。
面相KV cache卸载设计可训稀疏注意力
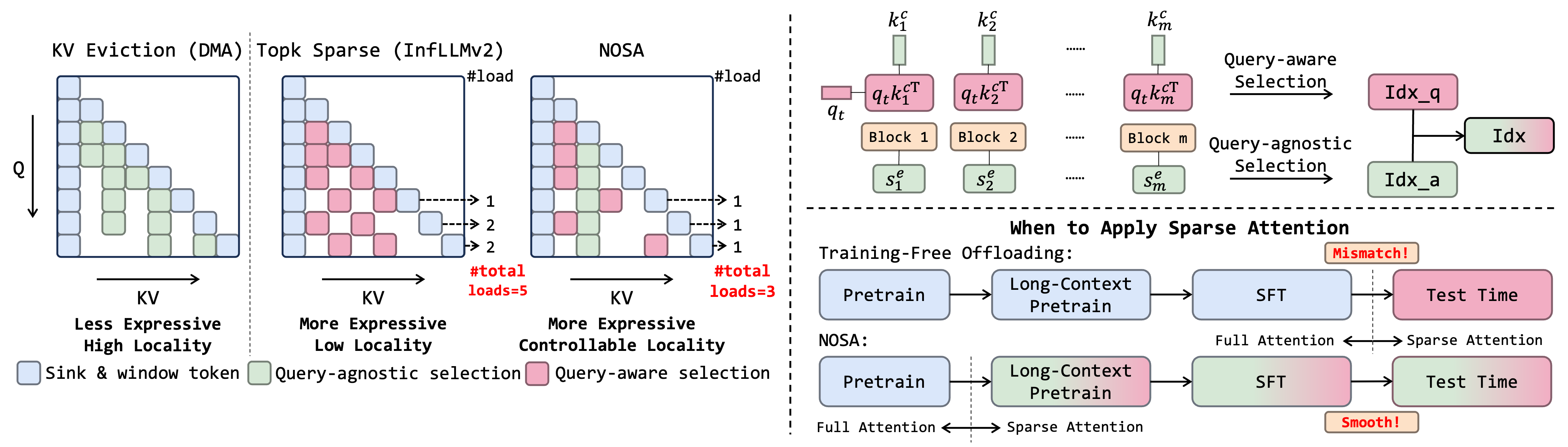
既然可训稀疏注意力的局部性不够好,我们在设计可训稀疏注意力时主要优化这一方面。一种比较简单的方式是构造一个局部性下界,让所有token选择的局部性必然好于这个下界。设第$t$个token选择的所有位置为$\Gamma(t)$,那么Topk稀疏注意力一定有$\lvert \Gamma(t)\rvert = k$。我们将其分解为查询相关/无关的选择,也就是$\Gamma(t) = \Gamma_q(t) + \Gamma_e(t), k = k_q+k_e$,并且让$\Gamma_e(t)$的选择遵循一个KV cache丢弃模式,即这一部分的选择一定不会从CPU上捞回token,那我们就能保证局部性一定好于$k_q/k$。
对于$\Gamma_q(t)$,我们直接采用InfLLMv2的方法来选择上下文块。每个块求均值得到一个块表示,用每个token的$q_t$点乘这个表示,然后选择Top-$k_q$个块即可。
对于$\Gamma_e(t)$,将查询无关选择实现为一个KV cache eviction模式即可。有非常多的eviction模式可选,例如我的工作Locret,还有近期的稀疏注意力工作DMA。经过我们的测试,发现DMA的一个小改进ED-DMA是最好的eviction head。详见我们的论文附录查看选择eviction head的过程。
有了上面两种选择,保持局部性就变得非常容易。首先先选择$k_q$个查询相关token,然后把他们的重要性分数设置为正无穷。接下来,在查询无关的重要性分数上去取Top-$k$来补足剩下的$k_e$个token即可。显然(或者不显然),这样选择能够保证当前token选的范围与上一个token的重合比例大于$k_e/k$。详见论文最后一页对该性质的证明。
现在,我们终于在算法层面设计了一个有局部性下界的可训练稀疏注意力方法。相较于没有下界的InfLLMv2(即如果足够幸运,两个相邻token的选择可以完全不一样),这一方法能够至少强制限制通过PCIe传输的token不超过某个比例。在我们的实践中,我们把$k_q/k$设置为0.25,也就是令局部性的下界为0.75. 虽然这一下界仍然十分低(考虑到InfLLMv2原生已经有超过80%的局部性),但是在图2d中,该设置依旧可以令局部性提升大约5%,也就是PCIe上传输的token减少到原本的1/2.
除了算法上的设计,我们还进行了系统上的设计与优化(NOSI)。由于HF实现的代码过于慢(详见附录的breakdown analysis),PCIe通信甚至都不是主要瓶颈。因此,我们实现了一套非常简单但有效的推理代码,将PCIe通信瓶颈充分暴露出来。由于系统优化在本工作中过于枯燥(但是非常的依赖hardworking),不在博客中过多介绍,详见我们的开源代码和论文第4章。
实验效果
主要关注以下方面:长文本输入、长推理、短文本通用任务,以及解码的吞吐。
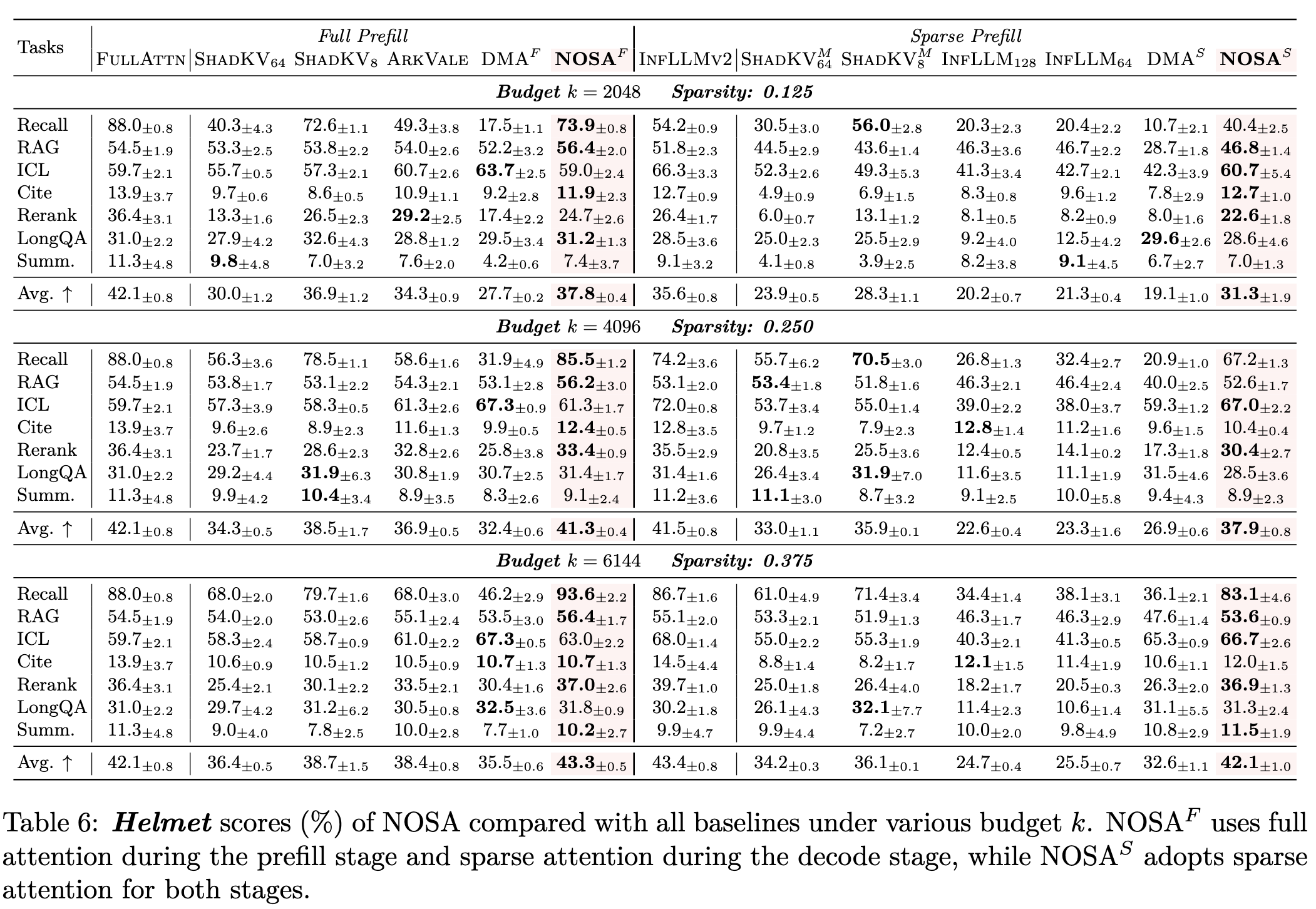
- 长文本输入:比传统的KV cache卸载方法效果更好。注:DMA的设计其实是eviction,所以不能做Recall。

- 短文本/长输出:NOSA在短文本上不掉点,在长文本上远超其他传统的KV cache卸载方法。传统KV cache卸载方法因为训推不一致,decode过程会累积误差,导致最终的生成崩掉。详见论文中这一部分的分析。
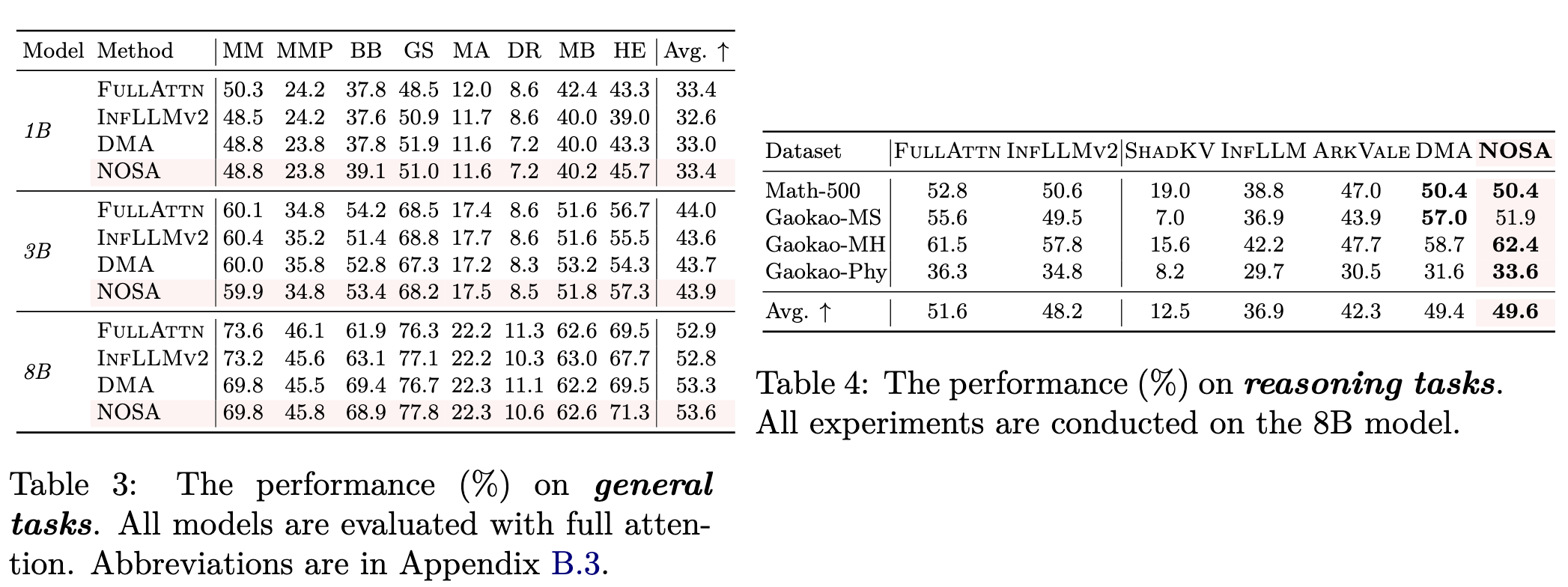
- 解码吞吐:在速度上超越其他baseline。在实现上,NOSI非常重要,因为HF太慢,不能体现NOSA的效果。可以看到,NOSA的局部性比InfLLMv2更好,所以解码吞吐也更高。
讨论
NOSA与NOSI只是稀疏注意力发挥更大作用的一个开始。之前,可训稀疏解决了训推不一致的问题并且成功做到了同时降低计算与访存;现在,我们通过NOSA又前进了一步,引入了一个局部性约束来加速大batch size下的解码吞吐,且整套解决方案完全可训。下一步,我们将把这一设计引入更多场景,例如LLM Serving或RL Rollout来实现更大程度的加速。
引用
如果我们的工作有帮助,请引用我们的论文。
@article{huang2025nosa,
title={NOSA: Native and Offloadable Sparse Attention},
author={Huang, Yuxiang and Wang, Pengjie and Han, Jicheng and Zhao, Weilin and Su, Zhou and Sun, Ao and Lyu, Hongya and Zhao, Hengyu and Wang, Yudong and Xiao, Chaojun and Han, Xu and Liu, Zhiyuan},
journal={arXiv preprint arXiv:2510.13602},
year={2025}
}