
Locret: 個人デバイスでの長文コンテキスト推論を可能にする
2024/09 こう うしょう @清華大学 & 香港科技大学 [中文][한국어][English]
要約: 私たちは Locret を紹介します。これは、分割されたプレフィルとキャッシュエビクションを利用した、軽量なトレーニングベースのKVキャッシュ圧縮手法です。Locretは、Phi-3-mini-128KおよびLlama-3.1-8B-instructに対して、それぞれ$20\times$および$8\times$のKVキャッシュ圧縮率を達成し、1 GPU時間未満のトレーニングで完了します。Locretは堅牢で、複数の効率的な推論手法と互換性があります。私たちの知る限り、LocretはLlama-3.1-8Bまたは同様のモデルを単一のNvidia 4090 GPUで展開できる最初のフレームワークであり、128Kの長文コンテキスト推論を生成品質を犠牲にせずに実行し、システム最適化を最小限に抑えることができます。
背景
消費者向けデバイス、エンドサイドLLM、および長文コンテキスト推論
近年、大規模言語モデル(LLM)の開発が急速に拡大しています。これらのモデルはほぼすべての分野でパフォーマンスの向上を示しており、開発者は現在、消費者向けデバイス専用に設計された、よりコンパクトなモデルの作成に注力しています。
消費者向けデバイス. LLMのユーザーエクスペリエンスを向上させるために、ハードウェアメーカーは、より安価で小型のGPUを設計および製造したり、AIモデルの総コストを削減するために、GPUとNPUを単一のSoCに統合しています。たとえば、Nvidia 4090は24GBのGPUメモリしか持たず、個人用コンピュータにインストールでき、その価格は2000米ドル以下に抑えられています。AppleやQualcommのような企業も、行列の乗算やスパース演算などのAI計算タスクに最適化されたデバイスを作成しています。しかし、これらのデバイスは依然として限られたGPUメモリと計算能力の制約に直面しています。
エンドサイドLLM. メモリと計算の制約を克服するために、エンドサイドLLMは、ユーザーのデバイス上で効率的なAIサービスを提供するように設計およびトレーニングされています。これらのモデルは通常、8B未満のコンパクトなサイズを持ち、1Bから3Bのパラメータ範囲です。MiniCPMは1.2Bから4Bの範囲のモデルを含んでおり、Phi-3-miniは約3B、Llama-3.2シリーズには1Bおよび3Bのモデルがあります。サイズが小さくなっても、これらのLLMはしばしば7B-8Bモデルに匹敵する優れた性能を発揮します。多段推論、難題探索、AI駆動型オペレーティングシステムなどのより複雑なタスクをサポートするために、これらのモデルはしばしば拡張されたコンテキスト長を処理するように設計されています。MiniCPM-3-4Bは最大32Kトークンを処理でき、Phi-3-mini-128KおよびLlama-3.2-1B/3Bは128Kの長文コンテキスト推論をサポートし、エンドサイドLLMが長文コンテキストタスクを効果的に実行できるようにします。
長文コンテキスト推論. 長文コンテキストLLMの推論は、従来の短文コンテキスト推論とは2つの重要な点で異なります:
-
注意メカニズムに対する計算負荷の増加
コンテキストの長さが増えると、注意スコアを計算するために必要な計算量が二乗で増加し、各トランスフォーマーブロック内の計算予算の大部分を消費します。
-
キーバリュー(KV)キャッシュのメモリ要件の増加
より長いコンテキストは、より大きなKVキャッシュを必要とし、ピークメモリ使用量が大幅に増加します。
これらの課題に対処するためには、長文コンテキストLLM推論のための計算コストを削減し、メモリをより効率的に管理するための革新的な技術が必要です。限られたメモリを持つ消費者向けデバイスは、これらのキャッシュを完全にサポートすることができないため、これらのデバイスで長文コンテキスト推論を行うためのKVキャッシュ圧縮アルゴリズムを開発することが非常に重要です。
既存の効率的な推論手法
KVキャッシュはしばしば推論のスループットのボトルネックとなるため、KVキャッシュを中心とした効率的な推論アルゴリズムがいくつか開発されてきました。これらはアルゴリズムの最適化とシステムの最適化に分類されます。
アルゴリズムの最適化:
-
量子化ベースの手法:
KVキャッシュは低ビット表現(例: 2ビットまたは4ビット)で保存されます。量子化はトークン単位またはチャンネル単位で適用されることがあります。
-
スパース性ベースの手法:
KVキャッシュのサイズは直接的に削減されません。代わりに、ヘッドやレイヤー内のパターンを特定することで、注意行列の計算を最適化し、計算すべき項目の数を削減します。
-
トークンドロップ:
- エビクションベース: 手動で設計されたスコアリング関数が各トークン(またはキャッシュユニット)の重要性を評価し、スコアが低いユニットがエビクションされます。
- トークンマージ(注意プールベース): 複数の隣接するキャッシュユニットが1つのユニットに統合されます。例えば、StreamingLLMでは、加算関数を使用してキャッシュユニットをプールします。
システムの最適化:
-
オフロードベース:
全体のキャッシュがチャンクに分割され、これらのチャンクのほとんどがCPUやディスクメモリにオフロードされます。最も関連性の高いチャンクのみが、チャンクごとのプレフィル中にGPUに戻されます。
-
ハードウェア認識アルゴリズム:
Flash-attentionやPage-attentionのような技術は、現代のGPUアーキテクチャを活用して、メモリ効率の良い注意カーネルを実装し、GPUメモリ使用量のピークを削減します。
-
より良いインフラの設計:
より効率的なプログラミング言語や分散推論フレームワークも、長文コンテキストLLM推論の効率性を向上させることができます。
効率的な長文コンテキスト推論のための各手法の利点と欠点の詳細な比較は、付録に記載されています。
推論の空間的複雑性
私たちの観点から、既存の推論技術は空間的複雑性に基づいて分類されることができます。$n$はコンテキストの長さを表し、$c\geq 1$は定数とします。
-
$O(n^2)$: 二次複雑性、例: 基本のフルKVキャッシュ推論。この複雑性は、長文コンテキスト推論シナリオにおいて、すべてのデバイスにとって非常に資源を消費します。
-
$O(c\times n)$: 線形複雑性、例: 分割されたプレフィルを使用したフルKVキャッシュ推論。この複雑性は、メモリ制約のある設定では依然として厳しいものです。KVキャッシュのサイズは、コンテキストの長さと共に増加します。
-
$O(n/c)$: 定数削減を伴う線形複雑性、例: 量子化、スパース注意、およびほとんどのシステム最適化。この複雑性はKVキャッシュのサイズを大幅に削減できますが、コンテキストの長さが128Kや1Mトークンに達する場合には非現実的になります。
-
$O(1)$: 定数複雑性。これはトークンドロップを通じて、またはRNNを使用して達成できます。固定キャッシュサイズを持つトークンドロップは$O(1)$であり、MambaやRWKVのようなRNNも推論中に定数複雑性を維持します。
長文コンテキスト推論の課題に対処するために、私たちは$O(1)$の複雑性を持つアルゴリズムを設計することを目指しています。私たちの目標は、既存のエビクションベースのアルゴリズムの精度を改善するためのより良いスコアリング関数を開発することです。 この関数を手動で設計する代わりに、私たちは正確なスコアリング関数を学習するためのトレーニングパラダイムを導入します。
Locret
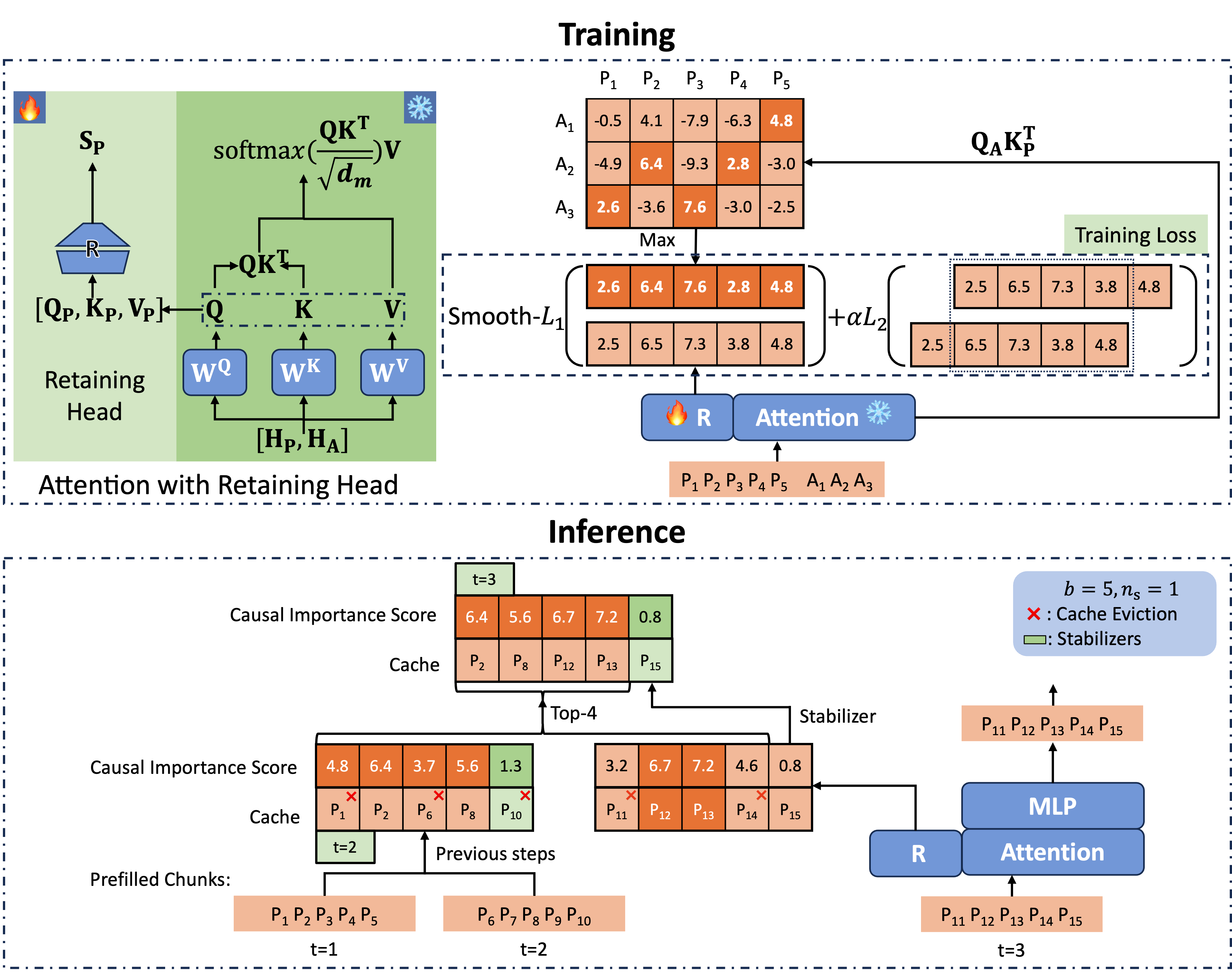
Locretの全体的なフレームワークは以下に示されています。まず、重要度スコア関数をトレーニングし、その後、キャッシュエビクションと分割プレフィルが行われます。
エビクションのためのトレーニング
Retaining Headと因果的重要度スコア
図2に示されているように、各アテンションモジュールにはRetaining Head($\mathbf{R}$で表記)という追加のパラメータを導入します。Retaining Headは、2つの行列と非線形活性化関数で構成されるFFNで定義されます。
\[\mathbf{R}(\mathbf{x}) = \sigma(\mathbf{xW_1})\mathbf{W_2}.\]Retaining Headへの入力は$[\mathbf{Q}, \mathbf{K}, \mathbf{V}]$の連結であり、KVヘッド値の数を出力します。これを因果的重要度スコア(CIS)と呼びます。以下にPyTorchスタイルのコード実装を示します:
cis = self.retaining_head_w2(
self.act(
self.retaining_head_w1(
torch.cat([h_q, h_k, h_v], dim=-1)
)
)
)
形式的には、次の式で書かれます。ここで、$\mathbf{\tilde S}[k]_j^{(i)}$は、$i$層の$j$ヘッドにおける$k$番目のトークンのCISスコアを表し、$i$層でのcis[:, k, j]です。
トレーニング目標
CISのラベルは次のように生成されます。Retaining Headは、単一のプロンプトと1つの回答からなる小規模な質問応答SFTデータセットでトレーニングされます。$i$層の$j$ヘッドにおける$k$番目のトークンのCISラベルは次の通りです:
\[\mathbf{S}[k]_j^{(i)} := \max_{n_q(d) \leq p \leq n_q(d) + n_a(d)}\left(\mathbf{Q}_j^{(i)}\mathbf{K}_{j}^{(i)T}\right)_{p, k},\]ここで、$n_q(d)$と$n_a(d)$は、データ$d$内のプロンプトと回答の長さを表します。
GQAモデルでは、QとKVの間のヘッド数は同じではないことに注意してください。そのため、同じKVグループ内のすべてのヘッドの最大値をCISラベルとして集約します。
$L$はレイヤー数、$h$はヘッド数を表します。トレーニングの目的は次の通りです:
\[\text{argmin}_{\mathbf{W_1}^{(i)}, \mathbf{W_2}^{(i)}, i=1, 2\cdots, L} \mathbb{E}_{d\in \mathcal{D}}\left[\sum_{i=1}^{L}\sum_{j=1}^{h}\sum_{k=1}^{n_q(d)}\mathcal{L}\left(\mathbf{\tilde S}[k]_j^{(i)}, \mathbf{S}[k]_j^{(i)} \right)\right]\]損失関数$\mathcal{L}$は次の通りです:
\[\mathcal{L}\left(\mathbf{\tilde S}[k]_j^{(i)}, \mathbf{S}[k]_j^{(i)}\right) = \text{Smooth-}\mathcal{L}_1\left(\mathbf{\tilde S}[k]_j^{(i)}, \mathbf{S}[k]_j^{(i)}\right) + \alpha \mathcal{L}_2\left(\mathbf{\tilde S}[k]_j^{(i)}, \mathbf{\tilde S}[k-1]_j^{(i)}\right),\]ここで、Smooth-$\mathcal{L}_1$は滑らかな1-ノルム、$\mathcal{L}_2$は2-ノルムです。
このアプローチに従って、私たちはLongAlpacaで3000ステップのトレーニングを行います。トレーニング時間は1GPU時間未満です。
Retaining Headを用いた推論
CISを予測するための正確なスコアリング関数が得られました。これを基に、分割プレフィルを行い、予測されたCISに基づいてキャッシュエビクションを実施します。
図2に示されているように、私たちは各レイヤーとヘッドで最後の$n_s$個のキャッシュユニットをstabilizersと呼び、性能を向上させるためにこれらを残します。静的な予算サイズ$b$を持つキャッシュセットを維持し、分割プレフィルを適用します。次のチャンクを処理する際、まずCISを計算し、stabilizersに$+\infty$を割り当て、次に現在のチャンクのキャッシュをキャッシュセットと連結します。最後に、CISスコアが最も高い$b-n_s$のキャッシュユニットを保持します。この方法により、キャッシュセットのサイズが固定されているため、空間的複雑性は一定に保たれます。Retaining Headは正確なスコアリングを行い、以降の処理に最も重要なキャッシュユニットを保持します。Locret推論の疑似コードは、アルゴリズム1に示されています。

ベンチマーク: 予算制約のある長文コンテキスト推論
パフォーマンスベンチマーク
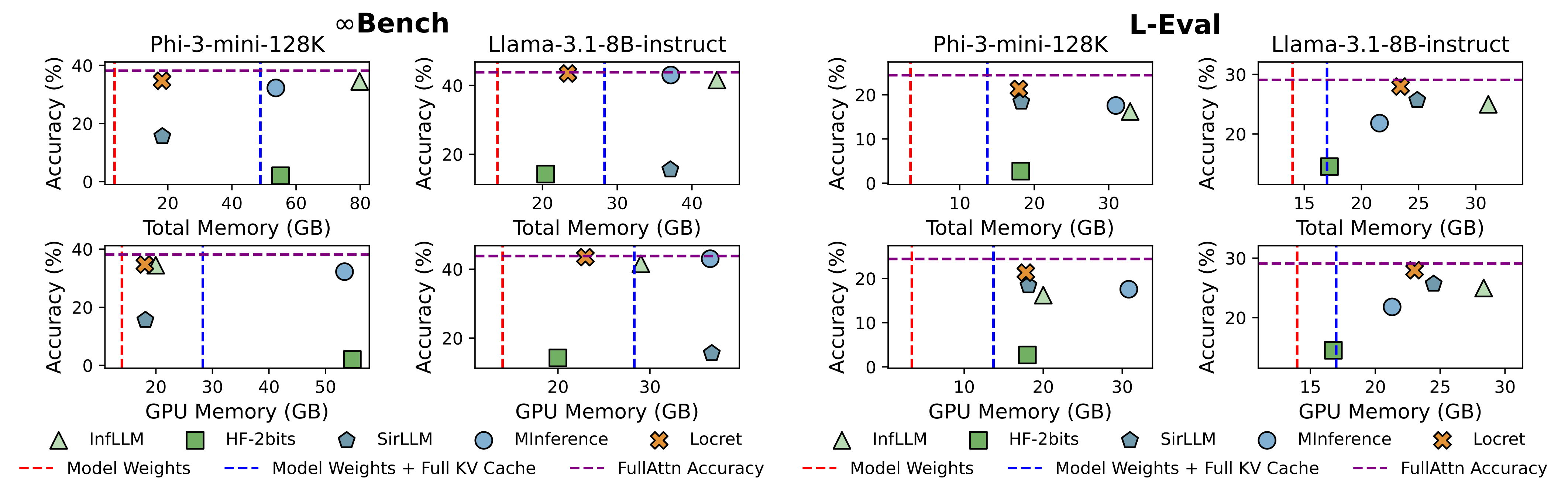
既存のアプローチに対応する5つのベースライン手法を選択し、Phi-3-mini-128KおよびLlama-3.1-8B-instructでLocretと比較しました。Locretの予算サイズは、それぞれ6000および16384に設定されました。ベースラインは次の通りです:
| 方法 | FullAttn | InfLLM | HF-2bits | SirLLM | MInference |
|---|---|---|---|---|---|
| カテゴリ | バニラフルKVキャッシュ | システム: オフロード | アルゴリズム: 量子化 | アルゴリズム: トークン削除-エビクション | アルゴリズム: スパース化 |
結果は図1に示されています。Locretは比較的少ないメモリを使用しながら、最高のベンチマークスコアを達成しました。Locretより少ないメモリを使用する方法は、一部またはすべての設定で完全に失敗しました。
スピードベンチマーク
Locretの推論速度も評価しました。私たちは、Nvidia 4090 1枚で他のすべてのベースライン手法と比較しました。このGPUは24GBのメモリしか持っていません。結果は次の通りです。いくつかの方法は、メモリ制約がある環境では動作しなかったため、OOMエラーが発生しないように入力コンテキストを切り詰めました。
| モデル | メトリクス | FullAttn | InfLLM | HF-2bits | SirLLM | MInference | Locret | HF-2bits* | MInference* |
|---|---|---|---|---|---|---|---|---|---|
| Phi-3-mini-128K | トークン/s | - | 2276.38 | - | 2352.20 | - | 5080.85 | 1098.51 | 4099.92 |
| Phi-3-mini-128K | コンテキスト長 | 128K | 128K | 128K | 128K | 128K | 128K | 30K | 14K |
| Phi-3-mini-128K | 正確度 | OOM | 99.83 | OOM | 1.69 | OOM | 100.00 | 0.00 | 13.56 |
| Llama-3.1-8B-instruct | トークン/s | - | 2287.66 | 1365.51 | 1589.75 | - | 3209.10 | 3680.06 | 5135.74 |
| Llama-3.1-8B-instruct | コンテキスト長 | 128K | 128K | 128K | 128K | 128K | 128K | 30K | 25K |
| Llama-3.1-8B-instruct | 正確度 | OOM | 100.00 | 35.59 | 1.69 | OOM | 100.00 | 26.78 | 20.34 |
量子化およびトークンマージとの直交性
以前の研究では、H2Oのようなエビクションベースの手法はKVキャッシュの量子化と組み合わせた場合に問題があることが示されています。しかし、Locretは量子化が適用されても堅牢です。
| 設定 | M | M-4bits | $-\Delta$ |
|---|---|---|---|
| M=FullAttn | 29.08 | 28.52 | 0.56 |
| M=Locret | 27.96 | 27.11 | 0.85 |
Locretにおける量子化による性能低下は、フルアテンション手法で観察されるものよりもわずかに大きいにすぎません。これは、Locretが量子化に適したアプローチであることを示しています。
さらに、エビクションされたキャッシュユニットを保存するために静的サイズの注意プールを維持することができます。LoCoCoは、H2Oによって特定されたノンヘビーヒッターに畳み込みを適用してこれを達成します。H2OをLocretに置き換えることで、両方の手法を組み合わせたものを得ることができます。
| 方法 | LoCoCo | Locret | 組み合わせ |
|---|---|---|---|
| L-Eval | 26.01 | 27.96 | 28.70 |
LocretはLoCoCoよりも高いスコアを達成し、組み合わせたアルゴリズムは両方の単独手法よりも優れた結果を示しました。これは、LocretがH2Oよりも正確なスコアリング関数を提供し、両方の手法が補完的であることを示しています。
引用
私たちのArXiV 論文を参照してください。
@article{huang2024locret,
title={Locret: Accelerating Long-Context LLM Inference with Retaining Heads},
author={Yuxiang Huang, Binhang Yuan, Xu Han, Chaojun Xiao, Zhiyuan Liu},
journal={arXiv preprint arXiv:2410.01805},
year={2024}
}
付録
| カテゴリ | タイプ | 長所 | 短所 | 例 |
|---|---|---|---|---|
| アルゴリズム | 量子化 | 4ビット以上の量子化による性能低下が最小限。実装が簡単。 | 2ビットでの性能低下が顕著。推論が遅い。特殊なハードウェアが必要。KVキャッシュサイズの削減が一定。 | KIVI, KVQuant |
| アルゴリズム | スパース化 | 非常に高速な推論速度。内部変数に対するランタイムGPUメモリ使用量が少ない。 | KVキャッシュサイズの削減がない。より密なモデル(例: MLA, GQA)では顕著な性能低下。 | MInference, FastGen |
| アルゴリズム | トークン削除 - エビクション | 高速な推論速度と簡単な実装。メモリ使用量が限定されている。 | 不正確なスコアリング関数による性能低下が顕著。 | H2O, SirLLM |
| アルゴリズム | トークン削除 - マージング | メモリ使用量が限定されている。 | いくつかのアルゴリズムは追加トレーニングが必要。事後トレーニングが不十分な場合、性能低下が顕著。 | StreamingLLM, LoCoCo |
| システム | オフロード | ほとんど性能低下がない。 | 限定されたI/O帯域幅のため、推論が非常に遅い。オフロードの最適化が必要。 | InfLLM, FlexGen |
| システム | ハードウェア認識アルゴリズム | 高いハードウェア効率、速い推論速度、精度の低下がない。 | KVキャッシュサイズの削減がない。特定のハードウェアアーキテクチャへの適応が必要。 | Flash-Attention, Page-Attention |
| システム | より優れたインフラ | 企業レベルのアプリケーションに適している。 | 開発が非常に難しい。さまざまなシナリオでの適用性が限定されている。 | KTransformers, HexGen |